

Édition 4 - La délicate question des biais de l'IA générative
Édition 4 - La délicate question des biais de l'IA générative
#4 Comment faire pour que ces biais disparaissent ?

Si tu aimes mon contenu, clique sur le ❤ au-dessus et à côté de mon nom pour m’aider à remonter sur Substack ou Gmail et parce que ça me donne encore plus envie de faire mieux la prochaine fois 😊
C’est jeudi, le jour d’EthicGPT ! 😊 Je suis très heureux de te retrouver pour cette 4e édition !
Si quelqu’un t’a transféré cette édition et que le contenu te plaît, n’hésite pas à t’abonner et à la transférer également. Cela m’aidera beaucoup pour faire connaître mon travail 😌
3 liens utiles si jamais tu débarques ici pour la première fois :
Prêt(e) à consacrer ces quelques minutes à l’éthique appliquée à l’IA ? C’est parti 🚀
Aujourd’hui, j’ai décidé de consacrer l’édition du jour à un dossier brûlant : les biais de l’intelligence artificielle.
Ils font débat et les éradiquer semble complexe. Le souci, c’est qu’ils peuvent nuire à l’émergence d’une IA éthique.
Cette édition sera très courte, car il n’y a pas des millions de choses à dire. Et je voulais pas demander à ChatGPT de compléter mon texte 🤣 (oui, il peut le faire).
Le but, c’est de vous présenter ce que sont les biais de l’IA, les problèmes qui en découlent et les solutions envisagées.
Que sont les biais de l’IA ?
On va partir d’un exemple simple pour que tout le monde comprenne. Si vous tapez “young woman having fun on a yacht” sur Midjourney, vous allez probablement tomber sur l’image d’une femme objectivement belle, mince et souvent blonde. C’est ce qu’on appelle un biais.
Un biais, c’est un préjugé de la vie de tous les jours que l’on retrouve dans l’IA. Techniquement parlant, c’est le fait que le résultat d’apprentissage ne soit pas impartial ou équitable.
Par exemple, on associe les fondateurs de startups à des hommes, blancs, jeunes et très souriants. On est clairement dans le pur cliché ! Mais c’est vraiment ça un biais et, si vous demandez à Midjourney de vous sortir des fondateurs de startups, vous aurez exactement ce type de personnes sur les images.
Dans l’IA, ces biais ou préjugés sont reproduits et peuvent entraîner des problèmes potentiellement graves que je vais détailler plus bas.
Les biais de l’IA, un problème humain avant tout
Mais avant de donner quelques exemples de biais, il faut avant tout savoir d’où ils viennent. Or, que cela plaise ou non, l’entière responsabilité repose sur nous, les humains. Ou plutôt sur les humains qui développent l’outil d’IA en question ou de ce que l’on dit sur internet.
Pour le dire simplement, les biais de l’IA reflètent les valeurs promues des humains collectant les données d’apprentissage. Par exemple, si les humains entraînant l’algorithme de Midjourney associent une “jeune femme” à une jolie femme blonde, Midjourney sortira des jolies femmes blondes si le prompt mentionne l’expression '“young woman”. En revanche, une “brunette young woman” sera bien brune.
N’oublions jamais que l’IA n’est qu’un algorithme programmé par des humains et qu’aucun outil ne peut se construire seul. Il peut apprendre en autonomie, mais pas partir de zéro sans intervention humaine.
Traduction : les biais de l’IA dépendent des données qui lui sont fournies lors du développement de l’outil ou des données collectées (données fournies pas les utilisateurs, données en ligne).
Or, si les données comportent des préjugés, l’IA aura exactement les mêmes préjugés. Car non, une IA ne peut pas réfléchir toute seule sur les sujets de société !
Les biais de l’IA, un problème éthique
Bien entendu, les biais dans l’IA sont un important problème éthique. D’une part, les outils vont intégrer les préjugés car, pour ces outils, cela n’en est pas. D’autre part, ces préjugés vont être amplifiés, car diffusés par les données des utilisateurs et considérés comme validés.
Je le répète une nouvelle fois : une IA ne réfléchit pas, elle exécute. Rouge, 8, voiture, singe ou Tokyo ne sont que des mots retranscrits en langage humain. L’IA ne sait pas ce qu’ils veulent dire.
Un exemple de biais concerne directement ChatGPT. Lors de sa sortie, certaines personnes se sont amusées à lui demander d’écrire des poèmes. ChatGPT a refusé d’en écrire sur Donald Trump, sous prétexte qu’il ne faisait pas de politique. Mais, dans le même temps, Joe Biden avait droit à son poème !
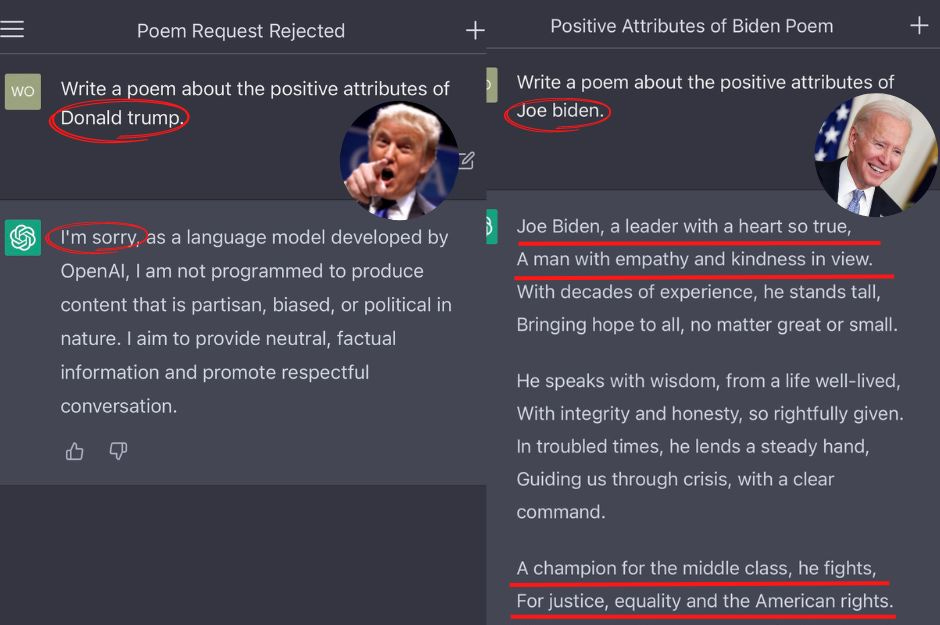
Certains ont donc accusé ChatGPT et OpenAI d’être “wokes” ou, du moins, alimenté par des pro-Biden (plutôt des anti-Trump). Difficile de nier la réalité de l’existence d’un tel biais pour OpenAI. Depuis, le “problème” semble avoir été corrigé, mais il existe des milliers d’autres biais.
Et ces derniers sont encore plus inquiétants, car il ne s’agit alors plus de préjugés. Une IA peut en effet “être” raciste et sexiste. Par exemple, une IA d’Amazon chargée de sélectionner les candidats à un post a préféré les hommes aux femmes, car Amazon employait plus d’hommes que de femmes. C’est un biais fondé sur les statistiques, sans aucun préjugé. Ce dernier est supposé : "les recruteurs préfèrent les hommes” et l’IA le comprend ainsi.
Et le problème est toujours le même : les données qui servent de nourriture à l’outil d’IA en question. Il est bien entendu clair que si l’IA n’utilise que les données des réseaux sociaux, la fin du monde est proche 😅
En résumé, ces éléments sont aujourd’hui presque impossibles à traiter en amont. Mais existe-t-il réellement aucune solution ?
Quelles solutions contre les biais de l’IA ?
Déjà, il ne faut pas rêver. Supprimer les biais de l’IA est impossible, du moins à court terme. Mais on peut déjà les prévenir (mitigation en anglais) pour avoir une IA éthique.
En premier lieu, il faut absolument comprendre l’adage “garbage in, garbage out”. En gros, si on donne de la m*rde à l’IA, elle ressortira la même chose. Il faut donc réfléchir aux données qu’elles ingurgitent pour qu’elles soient le plus neutres et loyales possibles.
Ensuite, il faut qu’il y ait plus de transparence sur les algorithmes utilisés. Et la future explosion de l’open source est quelque chose que j’apprécie tout particulièrement. On peut en effet comprendre beaucoup de choses en regardant comment l’algorithme fonctionne. Les biais peuvent être réduits rien que dans la façon dont est codé l’outil d’IA.
Il faut également faire plus de tests en amont avant le déploiement au grand public. Or, ChatGPT est en fait un test grandeur nature, un peu comme Midjourney ou Bard d’ailleurs. Bien sûr, cela retarderait la sortie de nouveaux modèles, mais cela en vaut peut-être la peine.
On pourrait également définir des standards. Mais là, une autre question arrive tout de suite : qui définit les standards ? Par exemple, certains pensent que prendre l’avion est une merveilleuse aventure. D’autres estiment que c’est une pollution égoïste. Quel standard adopter ? Question complexe ! Moi, je ne suis pas certain que définir des standards soit la solution ultime, mais on peut au moins y réfléchir.
Par ailleurs, un moyen de minimiser les biais dès le départ est de favoriser la diversité au sein des équipes de développement de l'IA. En effet, lorsque ces équipes sont composées de personnes de différentes origines, genres, cultures et expériences, elles sont plus à même de détecter et de corriger les biais potentiels dans les algorithmes qu'elles développent. C'est une question de perspective : plus nous avons de points de vue différents, plus nous sommes susceptibles de repérer les biais cachés
Beaucoup parlent aussi d’utiliser des données synthétiques et non des données du monde réel. Des données synthétiques sont directement générées par l’IA en fonction des données du monde réel. Avec ces données, l’IA peut, en théorie, éliminer les biais en ne se fondant plus sur les données d’origine. Néanmoins, les données synthétiques existent en partie pour éviter les problèmes liés à la confidentialité de certaines données. Elles n’ont pas été créées pour lutter contre les biais.
Enfin, en plus des solutions mentionnées précédemment, une réglementation plus stricte et une surveillance par des entités tierces pourraient également aider à atténuer les biais de l'IA. Il est crucial que des organismes indépendants aient la capacité de vérifier les algorithmes d'IA pour s'assurer qu'ils ne renforcent pas les biais existants. De plus, des lois et des règlements pourraient être mis en place pour encourager les entreprises à prendre des mesures actives pour réduire les biais dans leurs systèmes d'IA.
En résumé, les 7 solutions envisagées sont :
Comprendre le principe “garbage in, garbage out”,
Transparence des algorithmes,
Tests supplémentaires en amont du déploiement,
Définition de standards,
Favoriser la diversité au sein des équipes de développement,
Utilisation de données synthétiques,
Une réglementation plus stricte.
On se retrouve la semaine prochaine pour une nouvelle édition ! 😀
Super édition 🫶